Un árbol binario es una estructura de datos en la cual cada nodo siempre tiene un hijo izquierdo y un hijo derecho. No pueden tener más de dos hijos (de ahí el nombre «binario»). Si algún hijo tiene como referencia a null, es decir que no almacena ningún dato, entonces este es llamado un nodo externo. En el caso contrario el hijo es llamado un nodo interno. Usos comunes de los árboles binarios son los árboles binarios de búsqueda, los montículos binarios y Codificación de Huffman.
Definición de teoría de grafos

Un árbol binario sencillo de tamaño 9, 4 niveles y altura 3 (altura = máximo nivel – 1), con un nodo raíz cuyo valor es 2.
En teoría de grafos, se usa la siguiente definición: «Un árbol binario es un grafo conexo, acíclico y no dirigido tal que el grado de cada vértice no es mayor a 3». De esta forma sólo existe un camino entre un par de nodos.
Un árbol binario con enraizado es como un grafo que tiene uno de sus vértices, llamado raíz, de grado no mayor a 2. Con la raíz escogida, cada vértice tendrá un único padre, y nunca más de dos hijos. Si rehusamos el requerimiento de la conectividad, permitiendo múltiples componentes conectados en el grafo, llamaremos a esta última estructura un bosque..
Tipos de árboles binarios
Un árbol binario es un árbol con raíz en el que cada nodo tiene como máximo dos hijos.
Un árbol binario lleno es un árbol en el que cada nodo tiene cero o dos hijos.
Un árbol binario perfecto es un árbol binario lleno en el que todas las hojas (vértices con cero hijos) están a la misma profundidad (distancia desde la raíz, también llamada altura).
A veces un árbol binario perfecto es denominado árbol binario completo. Otros definen un árbol binario completo como un árbol binario lleno en el que todas las hojas están a profundidad n o n-1, para alguna n.
Un árbol binario es un árbol en el que ningún nodo puede tener más de dos subárboles. En un árbol binario cada nodo puede tener cero, uno o dos hijos (subárboles). Se conoce el nodo de la izquierda como hijo izquierdo y el nodo de la derecha como hijo derecho.
Recorridos sobre árboles binarios
Recorridos en profundidad
El método de este recorrido es tratar de encontrar de la cabecera a la raíz en nodo de unidad binaria. Ahora pasamos a ver la implementación de los distintos recorridos:
Recorrido en preorden
En este tipo de recorrido se realiza cierta acción (quizás simplemente imprimir por pantalla el valor de la clave de ese nodo) sobre el nodo actual y posteriormente se trata el subárbol izquierdo y cuando se haya concluido, el subárbol derecho. Otra forma para entender el recorrido con este metodo seria seguir el orden: nodo raiz, nodo izquierda, nodo derecha.
En el árbol de la figura el recorrido en preorden sería: 2, 7, 2, 6, 5, 11, 5, 9 y 4.
void preorden(tArbol *a)
{
if (a != NULL) {
tratar(a); //Realiza una operación en nodo
preorden(a->hIzquierdo);
preorden(a->hDerecho);
}
}
Implementación en pseudocódigo de forma iterativa:
push(s,NULL); //insertamos en una pila (stack) el valor NULL, para asegurarnos de que esté vacía
push(s,raíz); //insertamos el nodo raíz
MIENTRAS (s <> NULL) HACER
p = pop(s); //sacamos un elemento de la pila
tratar(p); //realizamos operaciones sobre el nodo p
SI (D(p) <> NULL) //preguntamos si p tiene árbol derecho
ENTONCES push(s,D(p));
FIN-SI
SI (I(p) <> NULL) //preguntamos si p tiene árbol izquierdo
ENTONCES push(s,I(p));
FIN-SI
FIN-MIENTRAS
Recorrido en postorden
En este caso se trata primero el subárbol izquierdo, después el derecho y por último el nodo actual. Otra forma para entender el recorrido con este metodo seria seguir el orden: nodo izquierda, nodo derecha, nodo raiz. En el árbol de la figura el recorrido en postorden sería: 2, 5, 11, 6, 7, 4, 9, 5 y 2.
void postorden(tArbol *a)
{
if (a != NULL) {
postorden(a->hIzquiedo);
postorden(a->hDerecho);
tratar(a); //Realiza una operación en nodo
}
}
Recorrido en inorden
En este caso se trata primero el subárbol izquierdo, después el nodo actual y por último el subárbol derecho. En un ABB este recorrido daría los valores de clave ordenados de menor a mayor. Otra forma para entender el recorrido con este metodo seria seguir el orden: nodo izquierda,nodo raiz,nodo derecha. En el árbol de la figura el recorrido en inorden sería: 2, 7, 5, 6, 11, 2, 5, 4, 9.
Esquema de implementación:
void inorden(tArbol *a)
{
if (a != NULL) {
inorden(a->hIzquierdo);
tratar(a); //Realiza una operación en nodo
inorden(a->hDerecho);
}
}
Grafos **
Historia
El trabajo de Leonhard Euler, en 1736, sobre el problema de los puentes de Königsberg es considerado el primer resultado de la teoría de grafos. También se considera uno de los primeros resultados topológicos en geometría (que no depende de ninguna medida). Este ejemplo ilustra la profunda relación entre la teoría de grafos y la topología.
En 1845 Gustav Kirchhoff publicó sus leyes de los circuitos para calcular el voltaje y la corriente en los circuitos eléctricos.
En 1852 Francis Guthrie planteó el problema de los cuatro colores que plantea si es posible, utilizando solamente cuatro colores, colorear cualquier mapa de países de tal forma que dos países vecinos nunca tengan el mismo color. Este problema, que no fue resuelto hasta un siglo después por Kenneth Appel y Wolfgang Haken, puede ser considerado como el nacimiento de la teoría de grafos. Al tratar de resolverlo, los matemáticos definieron términos y conceptos teóricos fundamentales de los grafos.
Estructuras de datos en la representación de grafos
Existen diferentes formas de almacenar grafos en una computadora. La estructura de datos usada depende de las características del grafo y el algoritmo usado para manipularlo. Entre las estructuras más sencillas y usadas se encuentran las listas y las matrices, aunque frecuentemente se usa una combinación de ambas. Las listas son preferidas en grafos dispersos porque tienen un eficiente uso de la memoria. Por otro lado, las matrices proveen acceso rápido, pero pueden consumir grandes cantidades de memoria.
Estructura de lista

Grafo de lista de adyacencia.
- lista de incidencia – Las aristas son representadas con un vector de pares (ordenados, si el grafo es dirigido), donde cada par representa una de las aristas.1
- lista de adyacencia – Cada vértice tiene una lista de vértices los cuales son adyacentes a él. Esto causa redundancia en un grafo no dirigido (ya que A existe en la lista de adyacencia de B y viceversa), pero las búsquedas son más rápidas, al costo de almacenamiento extra.
En esta estructura de datos la idea es asociar a cada vértice i del grafo una lista que contenga todos aquellos vértices j que sean adyacentes a él. De esta forma sólo reservará memoria para los arcos adyacentes a i y no para todos los posibles arcos que pudieran tener como origen i. El grafo, por tanto, se representa por medio de un vector de n componentes (si |V|=n) donde cada componente va a ser una lista de adyacencia correspondiente a cada uno de los vértices del grafo. Cada elemento de la lista consta de un campo indicando el vértice adyacente. En caso de que el grafo sea etiquetado, habrá que añadir un segundo campo para mostrar el valor de la etiqueta.
Estructuras matriciales
- Matriz de incidencia – El grafo está representado por una matriz de A (aristas) por V (vértices), donde [arista, vértice] contiene la información de la arista (1 – conectado, 0 – no conectado)
- Matriz de adyacencia – El grafo está representado por una matriz cuadrada M de tamaño n2, donde n es el número de vértices. Si hay una arista entre un vértice x y un vértice y, entonces el elemento mx,y es 1, de lo contrario, es 0.
Definiciones
Vértice
Artículo principal: Vértice (teoría de grafos)
Los vértices constituyen uno de los dos elementos que forman un grafo. Como ocurre con el resto de las ramas de las matemáticas, a la Teoría de Grafos no le interesa saber qué son los vértices.
Diferentes situaciones en las que pueden identificarse objetos y relaciones que satisfagan la definición de grafo pueden verse como grafos y así aplicar la Teoría de Grafos en ellos.
Grafo
Artículo principal: Grafo

En la figura, V = { a, b, c, d, e, f }, y A = { ab, ac, ae, bc, bd, df, ef }.
Un grafo es una pareja de conjuntos G = (V,A), donde V es el conjunto de vértices, y A es el conjunto de aristas, este último es un conjunto de pares de la forma (u,v) tal que  , tal que
, tal que  . Para simplificar, notaremos la arista (a,b) como ab.
. Para simplificar, notaremos la arista (a,b) como ab.
En teoría de grafos, sólo queda lo esencial del dibujo: la forma de las aristas no son relevantes, sólo importa a qué vértices están unidas. La posición de los vértices tampoco importa, y se puede variar para obtener un dibujo más claro.
Muchas redes de uso cotidiano pueden ser modeladas con un grafo: una red de carreteras que conecta ciudades, una red eléctrica o la red de drenaje de una ciudad.
Subgrafo
Un subgrafo de un grafo G es un grafo cuyos conjuntos de vértices y aristas son subconjuntos de los de G. Se dice que un grafo G contiene a otro grafo H si algún subgrafo de G es H o es isomorfo a H (dependiendo de las necesidades de la situación).
El subgrafo inducido de G es un subgrafo G’ de G tal que contiene todas las aristas adyacentes al subconjunto de vértices de G.
Definición:
Sea G=(V, A). G’=(V’,A’) se dice subgrafo de G si:
1- V’  V
V
2- A’ A
3- (V’,A’) es un grafo
- Si G’=(V’,A’) es subgrafo de G, para todo v
 G se cumple gr (G’,v)≤ gr (G, v)
G se cumple gr (G’,v)≤ gr (G, v)
G2 es un subgrafo de G.

Aristas dirigidas y no dirigidas
En algunos casos es necesario asignar un sentido a las aristas, por ejemplo, si se quiere representar la red de las calles de una ciudad con sus direcciones únicas. El conjunto de aristas será ahora un subconjunto de todos los posibles pares ordenados de vértices, con (a, b) ≠ (b, a). Los grafos que contienen aristas dirigidas se denominan grafos orientados, como el siguiente:
Las aristas no orientadas se consideran bidireccionales para efectos prácticos (equivale a decir que existen dos aristas orientadas entre los nodos, cada una en un sentido).
En el grafo anterior se ha utilizado una arista que tiene sus dos extremos idénticos: es un lazo (o bucle), y aparece también una arista bidireccional, y corresponde a dos aristas orientadas.
Aquí V = { a, b, c, d, e }, y A = { (a, c), (d, a), (d, e), (a, e), (b, e), (c, a), (c, c), (d, b) }.
Se considera la característica de «grado» (positivo o negativo) de un vértice v (y se indica como (v)), como la cantidad de aristas que llegan o salen de él; para el caso de grafos no orientados, el grado de un vértice es simplemente la cantidad de aristas incidentes a este vértice. Por ejemplo, el grado positivo (salidas) de d es 3, mientras que el grado negativo (llegadas) de d es 0.
Según la terminología seguida en algunos problemas clásicos de Investigación Operativa (p.ej.: el Problema del flujo máximo), a un vértice del que sólo salen aristas se le denomina fuente (en el ejemplo anterior, el vértice d); tiene grado negativo 0. Por el contrario, a aquellos en los que sólo entran aristas se les denomina pozo o sumidero (en el caso anterior, el vértice e); tiene grado positivo 0. A continuación se presentan las implementaciones en maude de grafos no dirigidos y de grafos dirigidos.En los dos casos, las especificaciones incluyen, además de las operaciones generadoras, otras operaciones auxiliares.
Ciclos y caminos hamiltonianos
Artículo principal: Ciclo hamiltoniano

Ejemplo de un ciclo hamiltoniano.
Un ciclo es una sucesión de aristas adyacentes, donde no se recorre dos veces la misma arista, y donde se regresa al punto inicial. Un ciclo hamiltoniano tiene además que recorrer todos los vértices exactamente una vez (excepto el vértice del que parte y al cual llega).
Por ejemplo, en un museo grande (al estilo del Louvre), lo idóneo sería recorrer todas las salas una sola vez, esto es buscar un ciclo hamiltoniano en el grafo que representa el museo (los vértices son las salas, y las aristas los corredores o puertas entre ellas).
Se habla también de camino hamiltoniano si no se impone regresar al punto de partida, como en un museo con una única puerta de entrada. Por ejemplo, un caballo puede recorrer todas las casillas de un tablero de ajedrez sin pasar dos veces por la misma: es un camino hamiltoniano. Ejemplo de un ciclo hamiltoniano en el grafo del dodecaedro.
Hoy en día, no se conocen métodos generales para hallar un ciclo hamiltoniano en tiempo polinómico, siendo la búsqueda por fuerza bruta de todos los posibles caminos u otros métodos excesivamente costosos. Existen, sin embargo, métodos para descartar la existencia de ciclos o caminos hamiltonianos en grafos pequeños.
El problema de determinar la existencia de ciclos hamiltonianos, entra en el conjunto de los NP-completos.
Caracterización de grafos
Grafos simples
Un grafo es simple si sólo 1 arista QUE une dos vértices cualesquiera. Esto es equivalente a decir que una arista cualquiera es la única que une dos vértices específicos.
Un grafo que no es simple se denomina Multigráfica o Gráfo múltiple.
Grafos conexos
Un grafo es conexo si cada par de vértices está conectado por un camino; es decir, si para cualquier par de vértices (a, b), existe al menos un camino posible desde a hacia b.
Un grafo es doblemente conexo si cada par de vértices está conectado por al menos dos caminos disjuntos; es decir, es conexo y no existe un vértice tal que al sacarlo el grafo resultante sea disconexo.
Es posible determinar si un grafo es conexo usando un algoritmo Búsqueda en anchura (BFS) o Búsqueda en profundidad (DFS).
En términos matemáticos la propiedad de un grafo de ser (fuertemente) conexo permite establecer con base en él una relación de equivalencia para sus vértices, la cual lleva a una partición de éstos en «componentes (fuertemente) conexas», es decir, porciones del grafo, que son (fuertemente) conexas cuando se consideran como grafos aislados. Esta propiedad es importante para muchas demostraciones en teoría de grafos. 
Grafos completos
Artículo principal: Grafo completo
Un grafo es completo si existen aristas uniendo todos los pares posibles de vértices. Es decir, todo par de vértices (a, b) debe tener una arista e que los une.
El conjunto de los grafos completos es denominado usualmente  , siendo
, siendo  el grafo completo de n vértices.
el grafo completo de n vértices.
Un , es decir, grafo completo de n vértices tiene exactamente  aristas.
aristas.
La representación gráfica de los como los vértices de un polígono regular da cuenta de su peculiar estructura.
Grafos bipartitos
Artículo principal: Grafo bipartito
Un grafo G es bipartito si puede expresarse como  (es decir, sus vértices son la unión de dos grupos de vértices), bajo las siguientes condiciones:
(es decir, sus vértices son la unión de dos grupos de vértices), bajo las siguientes condiciones:
- V1 y V2 son disjuntos y no vacíos.
- Cada arista de A une un vértice de V1 con uno de V2.
- No existen aristas uniendo dos elementos de V1; análogamente para V2.
Bajo estas condiciones, el grafo se considera bipartito, y puede describirse informalmente como el grafo que une o relaciona dos conjuntos de elementos diferentes, como aquellos resultantes de los ejercicios y puzzles en los que debe unirse un elemento de la columna A con un elemento de la columna B.
Operaciones en Grafos
Subdivisión elemental de una arista
 se convierte en
se convierte en 
Se reemplaza la arista  por dos aristas
por dos aristas 
 y un vértice w.
y un vértice w.
Después de realizar esta operación, el grafo queda con un vértice y una arista más.
Eliminación débil de un vértice
Si  y g(v) = 2 (Sea v un vértice del grafo y de grado dos) eliminarlo débilmente significa reemplazarlo por una arista que une los vértices adyacentes a v.
y g(v) = 2 (Sea v un vértice del grafo y de grado dos) eliminarlo débilmente significa reemplazarlo por una arista que une los vértices adyacentes a v.
se convierte en
Entonces e‘ y e» desaparecen y aparece
Homeomorfismo de grafos
Artículo principal: Homeomorfismo de grafos
Dos grafos G1 y G2 son homeomorfos si ambos pueden obtenerse a partir del mismo grafo con una sucesión de subdivisiones elementales de aristas.
Árboles
Artículo principal: Árbol (teoría de grafos)
Un grafo que no tiene ciclos y que conecta a todos los puntos, se llama un árbol. En un grafo con n vértices, los árboles tienen exactamente n – 1 aristas, y hay nn-2 árboles posibles. Su importancia radica en que los árboles son grafos que conectan todos los vértices utilizando el menor número posible de aristas. Un importante campo de aplicación de su estudio se encuentra en el análisis filogenético, el de la filiación de entidades que derivan unas de otras en un proceso evolutivo, que se aplica sobre todo a la averiguación del parentesco entre especies; aunque se ha usado también, por ejemplo, en el estudio del parentesco entre lenguas.
Grafos ponderados o etiquetados
En muchos casos, es preciso atribuir a cada arista un número específico, llamado valuación, ponderación o coste según el contexto, y se obtiene así un grafo valuado.
Formalmente, es un grafo con una función v: A → R+.
Por ejemplo, un representante comercial tiene que visitar n ciudades conectadas entre sí por carreteras; su interés previsible será minimizar la distancia recorrida (o el tiempo, si se pueden prever atascos). El grafo correspondiente tendrá como vértices las ciudades, como aristas las carreteras y la valuación será la distancia entre ellas.
Y, de momento, no se conocen métodos generales para hallar un ciclo de valuación mínima, pero sí para los caminos desde a hasta b, sin más condición.
[editar] Teorema de los cuatro colores
Artículo principal: Teorema de los cuatro colores

En 1852 Francis Guthrie planteó el problema de los cuatro colores.
Otro problema famoso relativo a los grafos: ¿Cuántos colores son necesarios para dibujar un mapa político, con la condición obvia que dos países adyacentes no puedan tener el mismo color? Se supone que los países son de un solo pedazo, y que el mundo es esférico o plano. En un mundo en forma de toroide; el teorema siguiente no es válido:
Cuatro colores son siempre suficientes para colorear un mapa.
El mapa siguiente muestra que tres colores no bastan: Si se empieza por el país central a y se esfuerza uno en utilizar el menor número de colores, entonces en la corona alrededor de a alternan dos colores. Llegando al país h se tiene que introducir un cuarto color. Lo mismo sucede en i si se emplea el mismo método.
La forma precisa de cada país no importa; lo único relevante es saber qué país toca a qué otro. Estos datos están incluidos en el grafo donde los vértices son los países y las aristas conectan los que justamente son adyacentes. Entonces la cuestión equivale a atribuir a cada vértice un color distinto del de sus vecinos.
Hemos visto que tres colores no son suficientes, y demostrar que con cinco siempre se llega, es bastante fácil. Pero el teorema de los cuatro colores no es nada obvio. Prueba de ello es que se han tenido que emplear ordenadores para acabar la demostración (se ha hecho un programa que permitió verificar una multitud de casos, lo que ahorró muchísimo tiempo a los matemáticos). Fue la primera vez que la comunidad matemática aceptó una demostración asistida por ordenador, lo que ha creado una fuerte polémica dentro de la comunidad matemática, llegando en algunos casos a plantearse la cuestión de que esta demostración y su aceptación es uno de los momentos que han generado una de las más terribles crisis en el mundo matemático.
Coloración de grafos
Artículo principal: Coloración de grafos
Definición: Si G=(V, E) es un grafo no dirigido, una coloración propia de G, ocurre cuando coloreamos los vértices de G de modo que si {a, b} es una arista en G entonces a y b tienen diferentes colores. (Por lo tanto, los vértices adyacentes tienen colores diferentes). El número mínimo de colores necesarios para una coloración propia de G es el número cromático de G y se escribe como C (G). Sea G un grafo no dirigido sea λ el número de colores disponibles para la coloración propia de los vértices de G. Nuestro objetivo es encontrar una función polinomial P (G,λ), en la variable λ, llamada polinomio cromático de G , que nos indique el número de coloraciones propias diferentes de los vértices de G, usando un máximo de λ colores.
Descomposición de polinomios cromáticos. Si G=(V, E) es un grafo conexo y e pertenece a Ε , entonces: P (G,λ)=P (G+e,λ)+P (G/e,λ), donde G/e es el grafo se obtene por contracción de aristas.
Para cualquier grafo G, el término constante en P (G,λ) es 0
Sea G=(V, E) con |E|>0 entonces, la suma de los coeficientes de P (G,λ) es 0.
Sea G=(V, E), con a, b pertenecientes al conjunto de vértices V pero {a, b}=e, no perteneciente a al conjunto de aristas E. Escribimos G+e para el grafo que se obtiene de G al añadir la arista e={a, b}. Al identificar los vértices a y b en G, obtenemos el subgrafo G++e de G.
Grafos planos
Artículo principal: Grafo plano

Un grafo es plano si se puede dibujar sin cruces de aristas. El problema de las tres casas y los tres pozos tiene solución sobre el toro, pero no en el plano.
Cuando un grafo o multigrafo se puede dibujar en un plano sin que dos segmentos se corten, se dice que es plano.
Un juego muy conocido es el siguiente: Se dibujan tres casas y tres pozos. Todos los vecinos de las casas tienen el derecho de utilizar los tres pozos. Como no se llevan bien en absoluto, no quieren cruzarse jamás. ¿Es posible trazar los nueve caminos que juntan las tres casas con los tres pozos sin que haya cruces?
Cualquier disposición de las casas, los pozos y los caminos implica la presencia de al menos un cruce.
Sea Kn el grafo completo con n vértices, Kn, p es el grafo bipartito de n y p vértices.
El juego anterior equivale a descubrir si el grafo bipartito completo K3,3 es plano, es decir, si se puede dibujar en un plano sin que haya cruces, siendo la respuesta que no. En general, puede determinarse que un grafo no es plano, si en su diseño puede encontrase una estructura análoga (conocida como menor) a K5 o a K3,3.
Establecer qué grafos son planos no es obvio, y es un problema que tiene que ver con topología.
Diámetro

En la figura se nota que K4 es plano (desviando la arista ab al exterior del cuadrado), que K5 no lo es, y que K3,2 lo es también (desvíos en gris).
En un grafo, la distancia entre dos vértices es el menor número de aristas de un recorrido entre ellos. El diámetro, en una figura como en un grafo, es la mayor distancia entre dos puntos de la misma.
El diámetro de los Kn es 1, y el de los Kn,p es 2. Un diámetro infinito puede significar que el grafo tiene una infinidad de vértices o simplemente que no es conexo. También se puede considerar el diámetro promedio, como el promedio de las distancias entre dos vértices.
El mundo de Internet ha puesto de moda esa idea del diámetro: Si descartamos los sitios que no tienen enlaces, y escogemos dos páginas web al azar: ¿En cuántos clics se puede pasar de la primera a la segunda? El resultado es el diámetro de la Red, vista como un grafo cuyos vértices son los sitios, y cuyas aristas son lógicamente los enlaces.
En el mundo real hay una analogía: tomando al azar dos seres humanos del mundo, ¿En cuántos saltos se puede pasar de uno a otro, con la condición de sólo saltar de una persona a otra cuando ellas se conocen personalmente? Con esta definición, se estima que el diámetro de la humanidad es de… ¡ocho solamente!
Este concepto refleja mejor la complejidad de una red que el número de sus elementos.
Referencias
http://es.wikipedia.org/wiki/%C3%81rbol_binario
http://es.wikipedia.org/wiki/Teor%C3%ADa_de_grafos
http://es.wikipedia.org/wiki/Teor%C3%ADa_de_grafos#Grafo

 esta formula calcula la cantidad de combinaciones que se pueden generar con n y r , realmente se le pueden llamar de la forma que se desee n combinacion con m ,n=numero de variables totales, m=numero de variables que se combinaran.
esta formula calcula la cantidad de combinaciones que se pueden generar con n y r , realmente se le pueden llamar de la forma que se desee n combinacion con m ,n=numero de variables totales, m=numero de variables que se combinaran.
Referencias http://assembly-marcelinha.googlecode.com/files/EnsAmelia.pdf http://bluemaster.iu.hio.no/edu/dark/lin-asm/syscalls.html http://www.itch.edu.mx/academic/industrial/sabaticorita/_private/07Combinaciones.htm



































































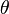






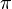


























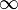
































![x_i=\sqrt[n]{\frac{a_i}{b_i}}](https://i0.wp.com/upload.wikimedia.org/math/0/6/b/06bbd3c418d492f067e8a0a4da16a37c.png)








 0 \\ x^2 & si\;no \end{matrix} \end{cases}» />
0 \\ x^2 & si\;no \end{matrix} \end{cases}» />

 – matriz de distancias.
– matriz de distancias. – distancia del enlace entre el nodo i y el nodo j.
– distancia del enlace entre el nodo i y el nodo j.





 .
.
")

















